Jakarta, odishanewsinsight.com – When I think about modern data systems, one of the most important foundations is the ability to move data reliably from one place to another while preserving quality and usefulness. Raw data rarely arrives in a form that is immediately ready for analysis, reporting, or operational use. It often needs to be collected, cleaned, standardized, enriched, and loaded into a structured destination. That is why ETL Processes matter so much. They provide the framework that turns scattered, inconsistent inputs into dependable data assets.
Why ETL Processes Matter

In my experience, ETL Processes matter because jonitogel data is only valuable when it can be trusted and used effectively. Organizations often collect information from multiple systems, such as applications, databases, APIs, files, and event streams. Without a robust pipeline, these sources can remain fragmented, inconsistent, and difficult to analyze together.
ETL processes solve this by creating a structured path for data ingestion and transformation. They help ensure that records are extracted correctly, transformed into usable formats, and loaded into systems where teams can access them confidently. This supports better reporting, cleaner analytics, and more reliable decision-making.
There is also a strong connection to technical Knowledge here. Designing ETL well requires understanding source systems, schema behavior, validation rules, transformation logic, timing, and downstream use cases.
My Perspective on Pipeline Design
What changed my understanding of ETL Processes was realizing that pipeline design is not just about moving data quickly. At first, it can seem like the main goal is automation. But over time, I saw that robustness matters even more than speed. A fast pipeline that produces incomplete, duplicated, delayed, or inconsistent data creates problems throughout the system.
That is what makes ETL design so important. A strong pipeline should not only move data efficiently. It should also handle failures gracefully, maintain data integrity, scale with demand, and remain understandable for the teams who depend on it. In practice, good ETL is as much about reliability and clarity as it is about transformation logic.
Core Stages of ETL Processes
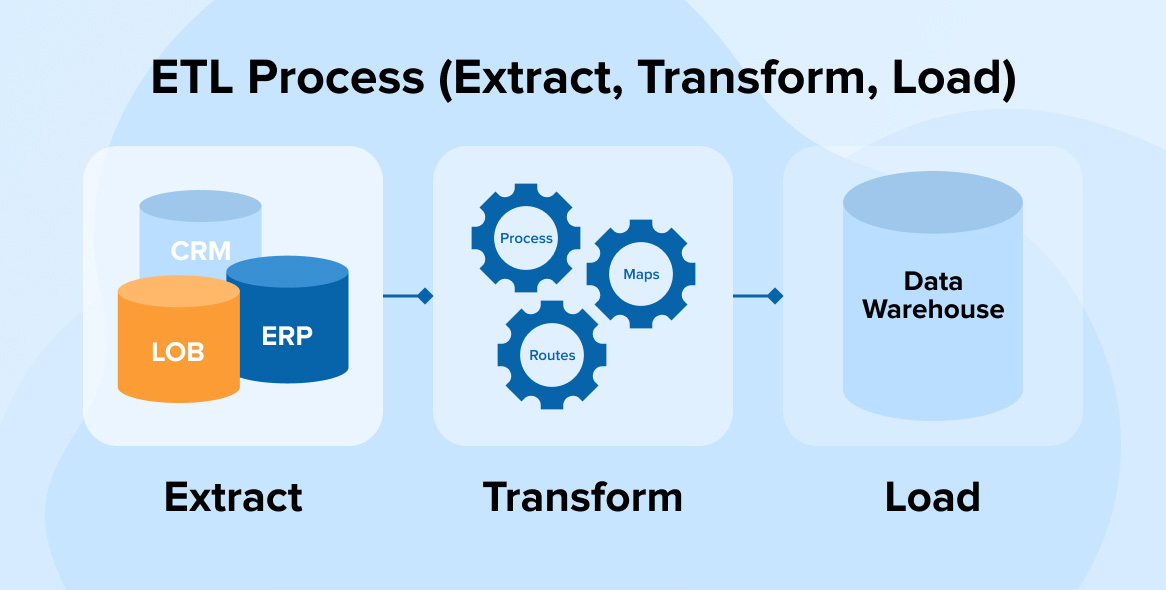
I think ETL Processes become easier to understand when their main stages are separated clearly.
Extract
Data is collected from source systems such as applications, APIs, logs, flat files, or databases.
Transform
Raw information is cleaned, mapped, standardized, validated, joined, aggregated, or enriched.
Load
The processed data is delivered into a target system such as a warehouse, database, or analytics platform.
These stages may sound straightforward, but each one involves design choices that affect quality and performance.
Common Challenges in ETL Pipeline Design
I have noticed that several issues can weaken ETL Processes if they are not addressed early.
Inconsistent source data
Different systems often use different formats, field names, and rules.
Data quality problems
Missing values, duplicates, and invalid records can spread through the pipeline.
Poor error handling
Pipelines that fail silently or unclearly are difficult to trust and maintain.
Scaling limitations
As data volume grows, weak designs can become slow or unstable.
Tight coupling
Pipelines that are too dependent on one source or schema can break easily when systems change.
Practical Principles for Robust ETL Processes
I believe ETL Processes become far more reliable when teams follow a few core principles.
Validate data early
Quality checks at the beginning reduce downstream issues.
Make transformations explicit
Clear, documented logic improves maintainability and trust.
Build for failure recovery
Retries, logging, alerts, and checkpointing help pipelines recover safely.
Monitor continuously
Performance, freshness, and error rates should be visible at all times.
Design for scale
Pipelines should handle larger data volumes without major redesign.
Keep lineage clear
Teams should be able to trace where data came from and how it changed.
Below is a simple overview of key pipeline elements:
| ETL Element | Why It Matters | Practical Example |
|---|---|---|
| Extraction | Brings source data into the pipeline | Pulling records from APIs and databases |
| Transformation | Improves usability and consistency | Standardizing date formats and removing duplicates |
| Loading | Delivers data for analysis or operations | Writing cleaned data into a warehouse |
| Validation | Protects data quality | Rejecting records with missing required fields |
| Monitoring | Supports reliability | Tracking failed jobs and delayed updates |
These elements work together to make ETL pipelines dependable rather than fragile.
Why ETL Processes Matter Beyond Data Movement
I think ETL Processes matter because they shape the quality of everything built on top of data. Dashboards, machine learning models, reports, automation systems, and strategic decisions all depend on the integrity of the underlying pipeline. If the ingestion and transformation process is weak, every downstream output becomes less reliable.
That is why ETL design is not just an engineering detail. It is a core part of data trust. Well-designed pipelines create consistency, visibility, and confidence across the organization. They make data more than just available. They make it usable.
Final Thoughts
For me, ETL Processes are essential to building robust systems for data ingestion and transformation. They provide the structure needed to collect raw inputs, improve data quality, and deliver information in forms that teams can depend on.
That is why careful pipeline design deserves serious attention. Strong ETL processes do more than move data from source to destination. They create the reliability, clarity, and scalability that modern data work requires.
Explore our “Technology” category for more insightful content!
Don't forget to check out our previous article: Virtual Servers: Deploying Scalable Virtualized Infrastructure in the Cloud