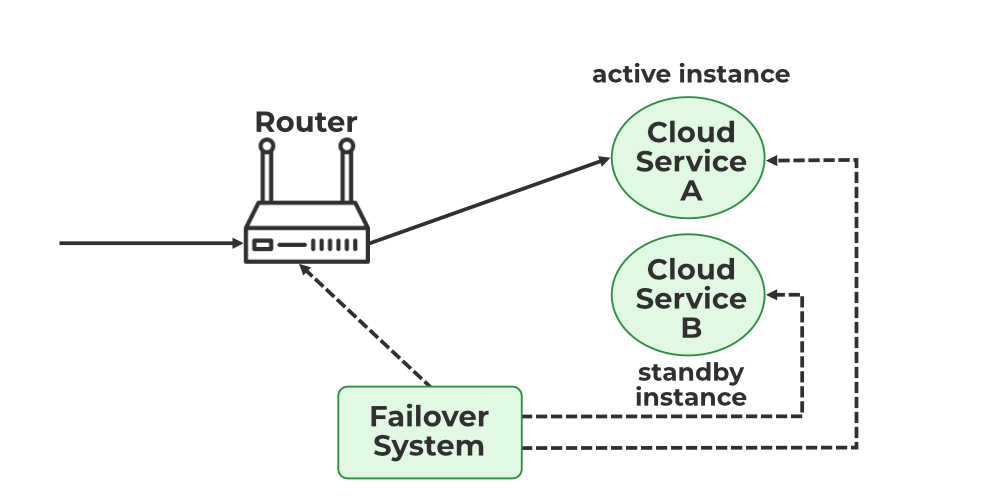
Jakarta, odishanewsinsight.com – Failover Systems are a fundamental part of resilient infrastructure, designed to keep applications and services available when primary components fail. In modern IT environments, outages can result from hardware faults, software crashes, network disruptions, power loss, or regional service incidents. A failover system addresses these risks by automatically or manually switching workloads, traffic, or operations from a failed component to a standby or secondary one, minimizing downtime and preserving service continuity.
What makes Failover Systems especially important is their role in reducing the business and operational impact of unexpected failure. Whether supporting web applications, databases, cloud platforms, or enterprise networks, failover design ensures that service availability does not depend entirely on a single point of operation. In practical terms, it is the infrastructure equivalent of having a spare parachute and hoping the first one remains a purely theoretical success story.
What Failover Systems Are
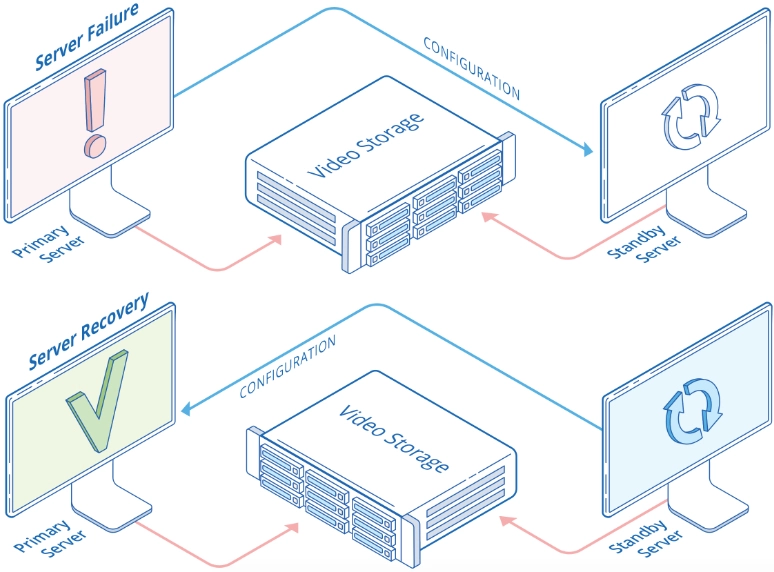
Failover Systems refer to infrastructure and operational mechanisms that detect failures and shift service responsibilities to backup resources so applications can continue functioning. These systems may involve redundant servers, replicated databases, secondary network paths, standby clusters, backup power, or geographically separate sites. The goal is not merely to have extra components, but to ensure those components can assume responsibility quickly and correctly when needed.
Common features associated with Failover Systems include:
- Redundant hardware or service instances
- Automatic failure detection and switchover
- High availability architecture
- Backup network and power pathways
- Data replication between primary and secondary systems
- Load balancer or DNS-based rerouting
- Reduced single points of failure
- Support for business continuity planning
These features explain why Failover Systems are essential to modern uptime-focused infrastructure.
Why Failover Systems Matter
Failover Systems matter because uninterrupted services depend on more than reliable primary infrastructure.
Availability Protection
They help applications remain reachable and functional during component or service failure.
Risk Reduction
They reduce the operational impact of outages caused by hardware, software, or network problems.
Business Continuity
They support critical services that cannot tolerate prolonged downtime.
Customer Trust
Reliable availability helps preserve user confidence and service credibility.
Operational Resilience
They strengthen an organization’s ability to absorb disruptions without total service collapse.
These strengths explain why Failover Systems are central to resilient infrastructure design.
Core Characteristics of Failover Systems
Their value becomes clearer when their main capabilities are viewed together.
| Characteristic | Description | Why It Matters |
|---|---|---|
| Redundancy | Duplicate resources are available if primary ones fail | Prevents single-point dependency |
| Failure detection | Monitoring identifies outages or degraded health | Enables timely failover |
| Switchover mechanism | Traffic or workloads move to backup systems | Preserves service continuity |
| Data replication | Secondary systems receive updated application state or data | Reduces recovery loss |
| Recovery planning | Defined procedures restore normal operation after incident | Supports stable long-term recovery |
Together, these characteristics show why Failover Systems are both a technical safeguard and a continuity strategy.
How Failover Systems Are Commonly Applied
Failover Systems are commonly applied in web hosting environments, database clusters, cloud architectures, enterprise applications, telecom infrastructure, and mission-critical systems such as finance, healthcare, and public services. They may be implemented through active-passive or active-active configurations, regional replication, automated cluster management, or traffic routing solutions such as load balancers and DNS failover. Depending on the business requirement, failover can be designed for server-level, application-level, network-level, or site-level continuity.
It is especially associated with:
- High availability architecture
- Disaster recovery planning
- Redundant server environments
- Multi-zone and multi-region deployment
- Database replication and clustering
- Load-balanced application platforms
- Critical service continuity
This broad application range shows how Failover Systems support uninterrupted services across different infrastructure layers.
Challenges of Building Failover Systems
While Failover Systems offer strong resilience benefits, they also introduce design and operational complexity.
Cost
Redundant infrastructure, replication, and monitoring increase operational and capital expense.
Architectural Complexity
Designing correct failover behavior requires careful planning across systems, networking, and state management.
Consistency Risks
Data synchronization between primary and backup systems must be handled carefully to avoid divergence or loss.
Testing Requirements
Failover plans are only trustworthy if exercised regularly through controlled testing.
False Confidence
A backup environment that exists on paper but fails in practice can be more dangerous than no backup at all.
These trade-offs show that Failover Systems require both investment and disciplined validation.
Why It Remains Important
Failover Systems remain important because digital services are expected to be available continuously, even in the face of unexpected disruption. As organizations become more dependent on online systems, cloud infrastructure, and real-time applications, the tolerance for downtime becomes smaller. Failover design helps meet this expectation by ensuring that failure does not automatically become outage. It turns resilience from an aspiration into an engineered capability.
It continues to stand out because it provides:
- Better service availability
- Reduced outage impact
- Stronger infrastructure resilience
- Improved continuity for critical operations
- A practical foundation for high availability strategy
This is why Failover Systems remain a central pillar of uninterrupted service architecture.
Final Thoughts
Failover Systems highlight the importance of planning for failure rather than pretending it will remain politely theoretical. Their value lies in keeping services available through redundancy, automated switchover, and continuity-focused architecture. Whether supporting applications, networks, or entire platforms, failover systems are a crucial part of building resilient infrastructure that can withstand disruption without bringing operations to a halt.
The key takeaway is simple. Failover Systems matter because they help organizations maintain uninterrupted services by ensuring infrastructure can recover from failure quickly and reliably.
Explore our “”Technology“” category for more insightful content!
Don't forget to check out our previous article: Circuit Breaker: Enhancing System Resilience with Fault-Tolerance Patterns